Banja Lab / Benchmarks / Test
UI-0005UI components · easy
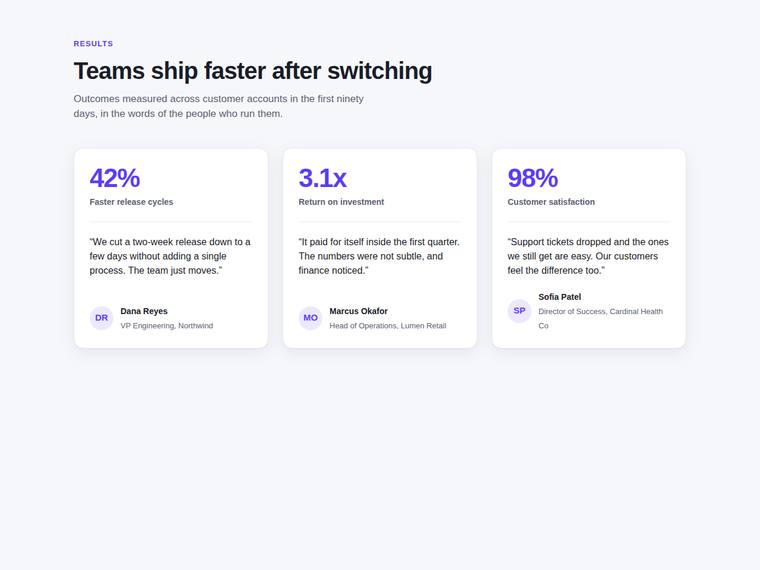
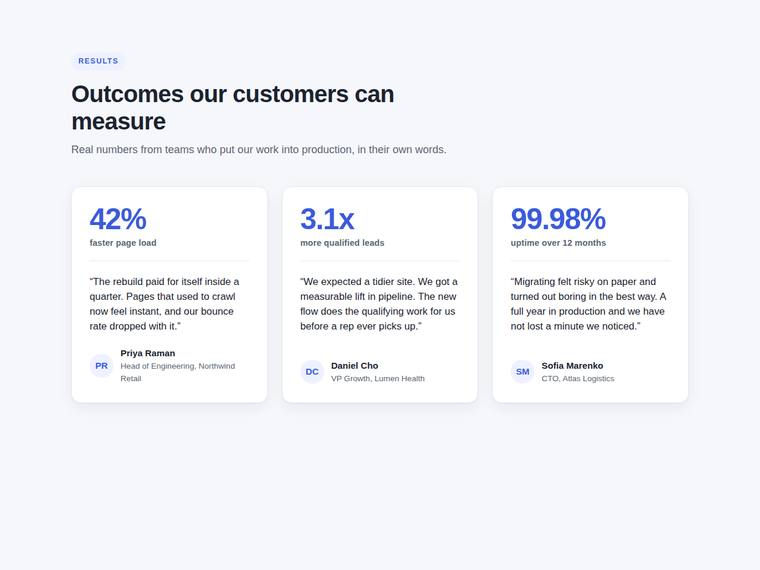
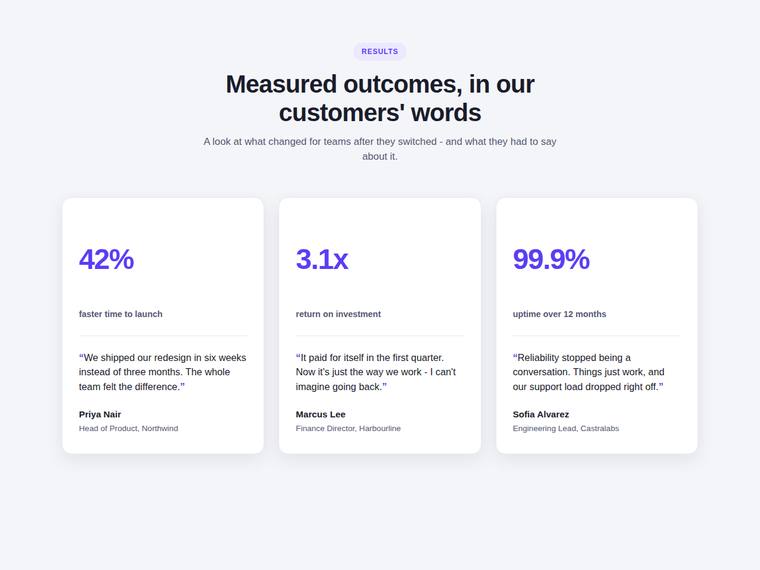
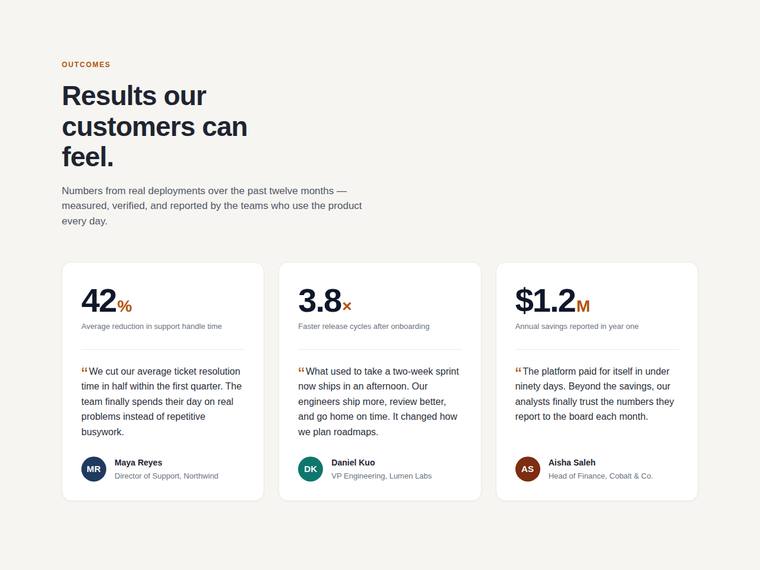
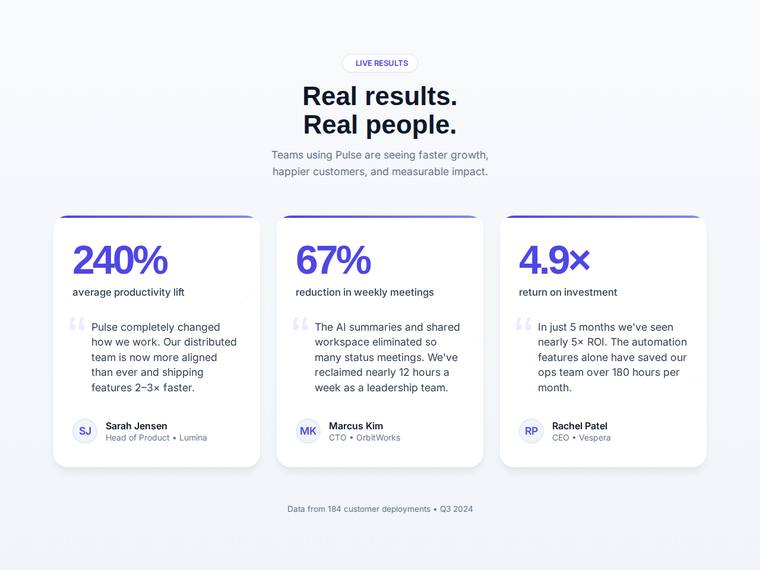
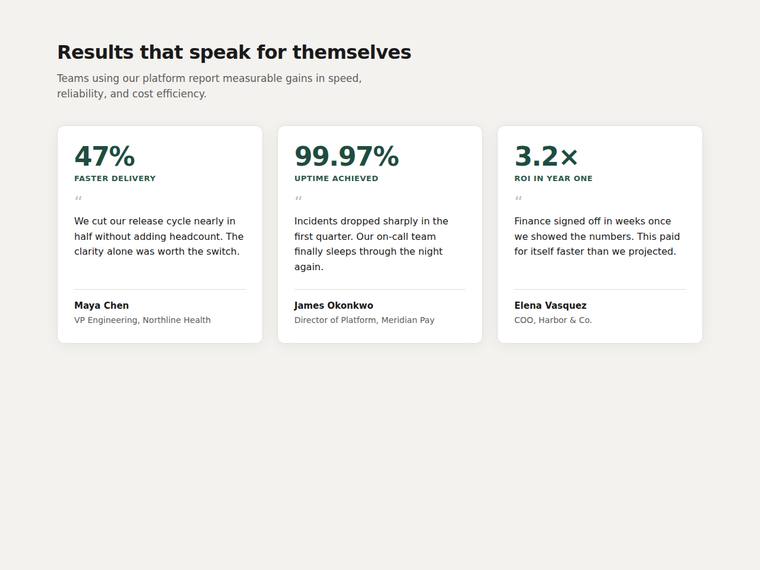
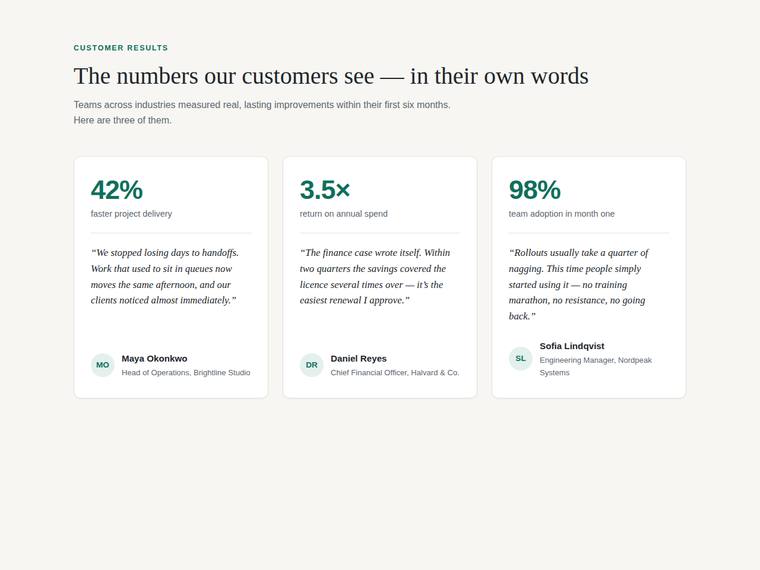
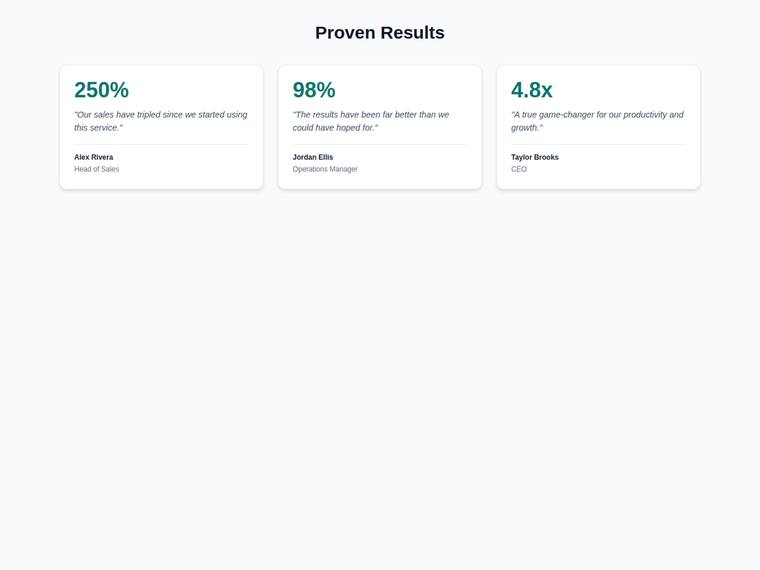
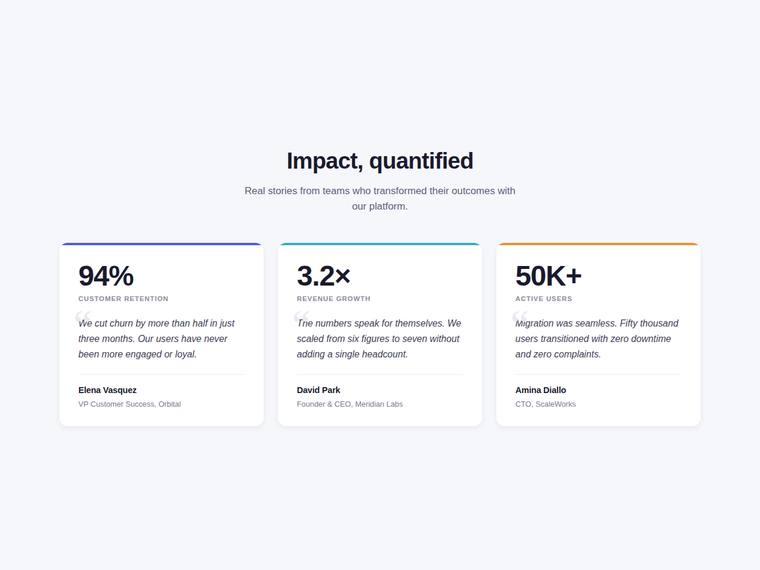
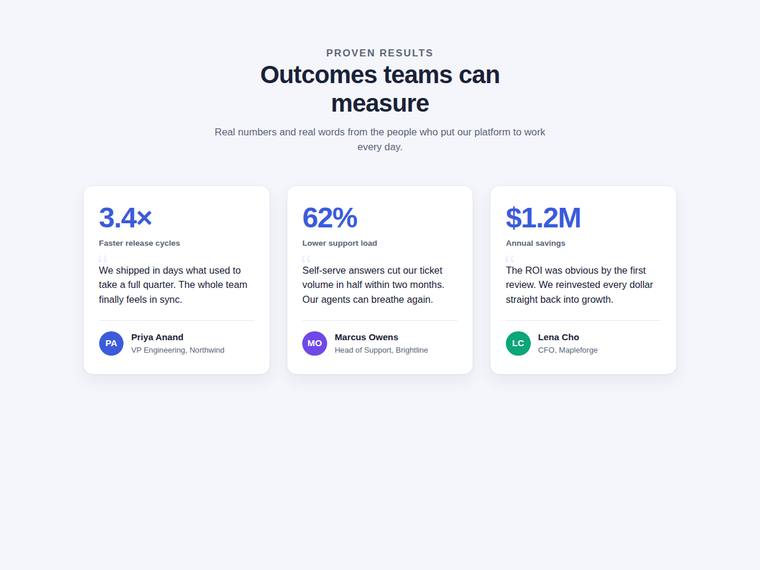
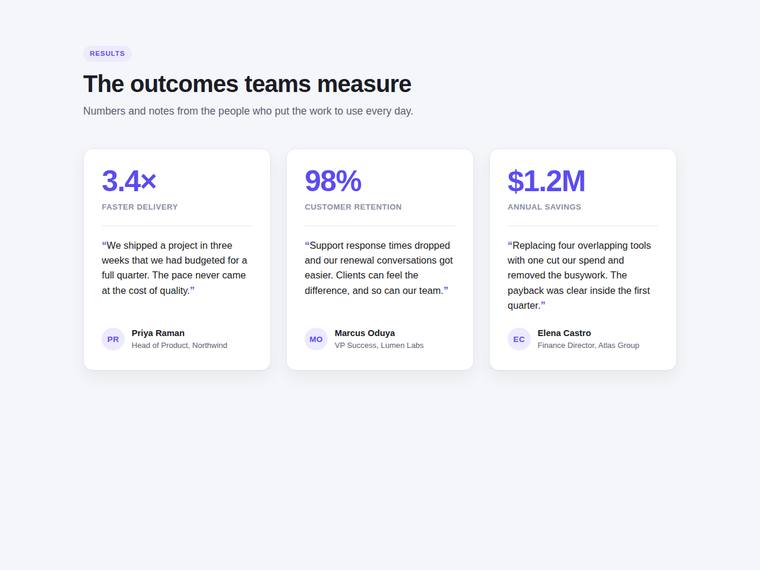
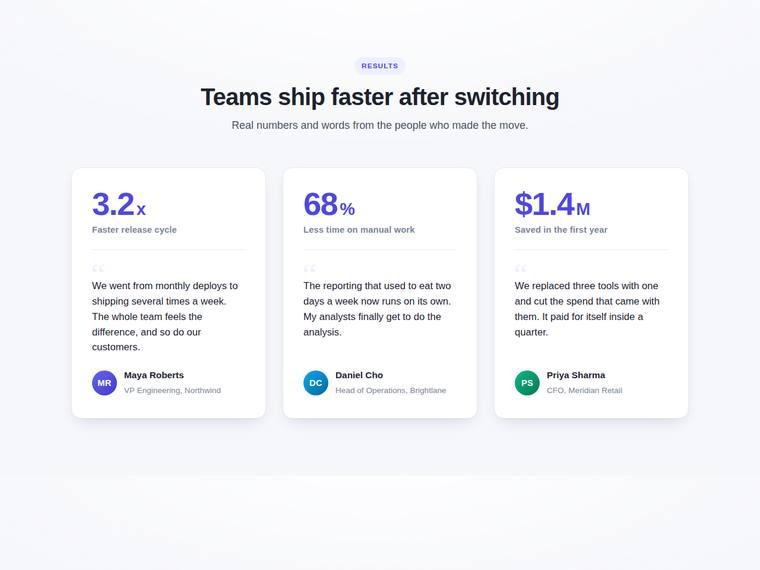
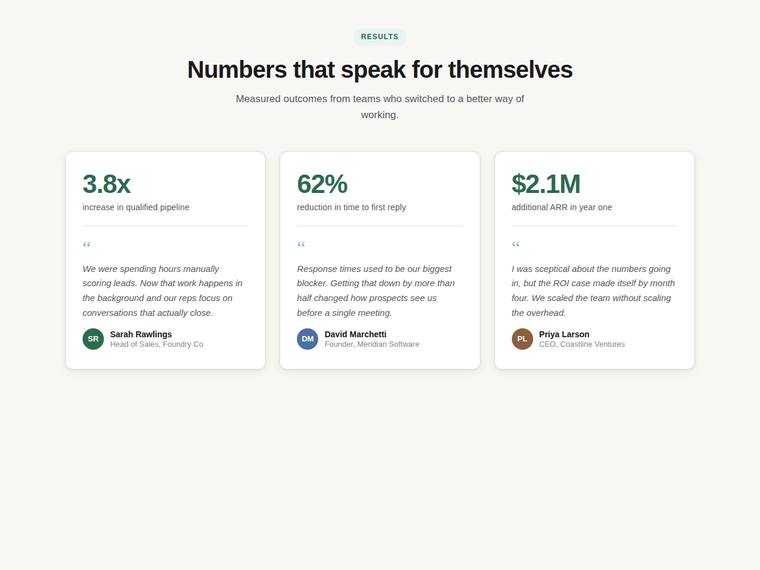
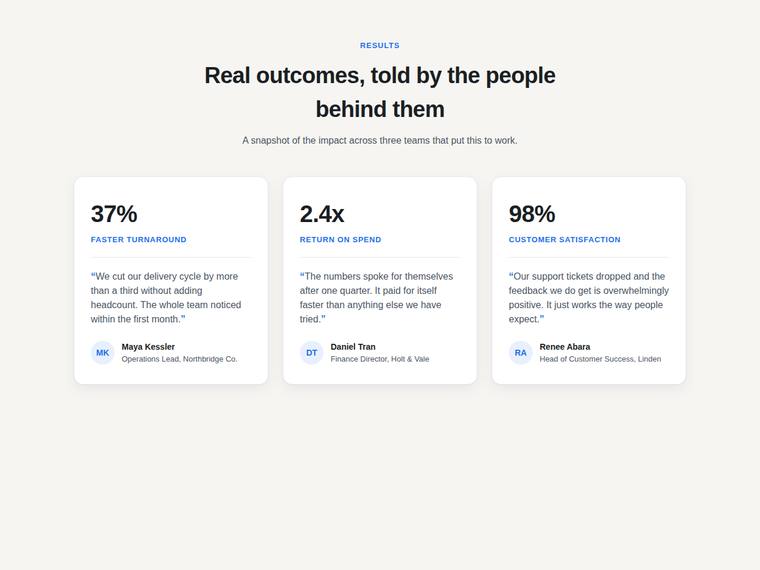
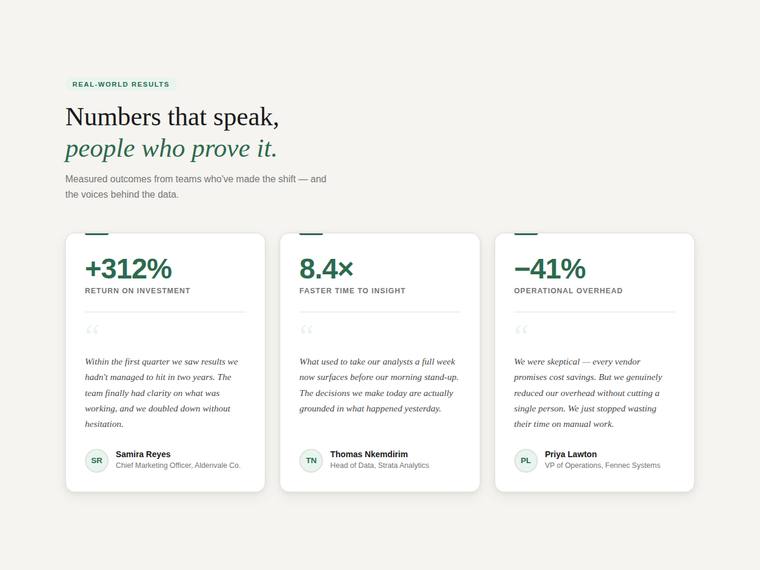
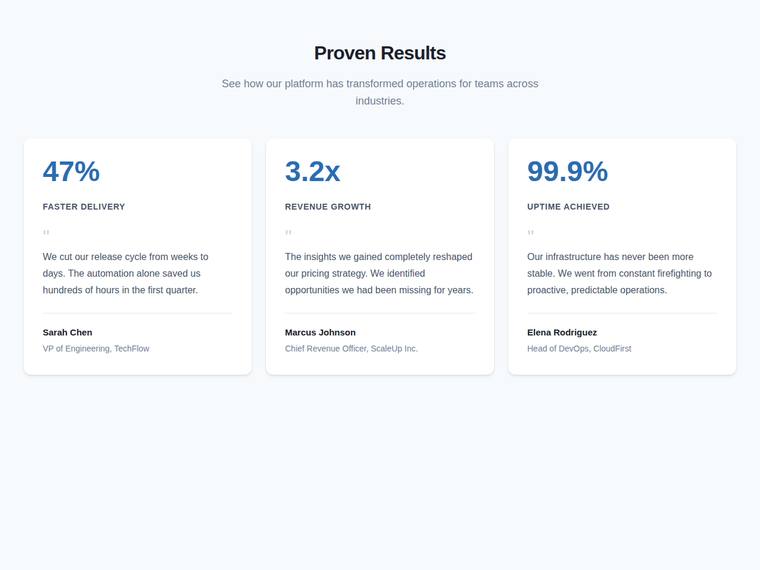
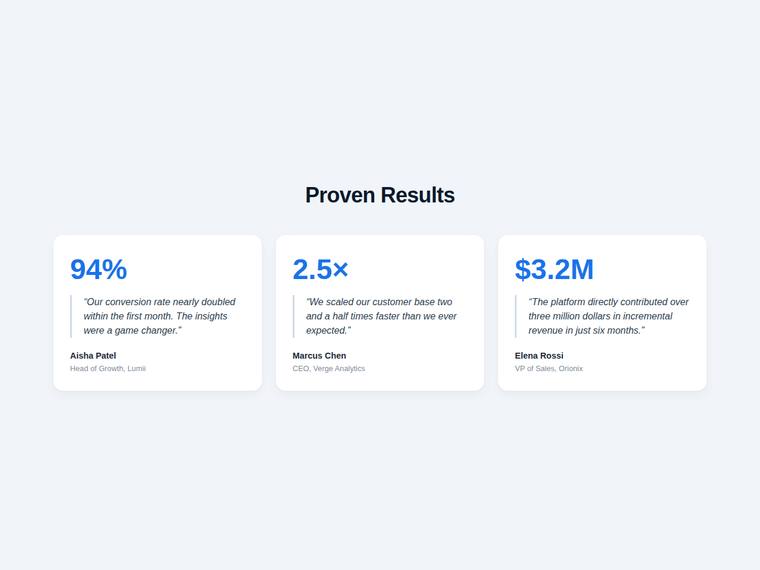
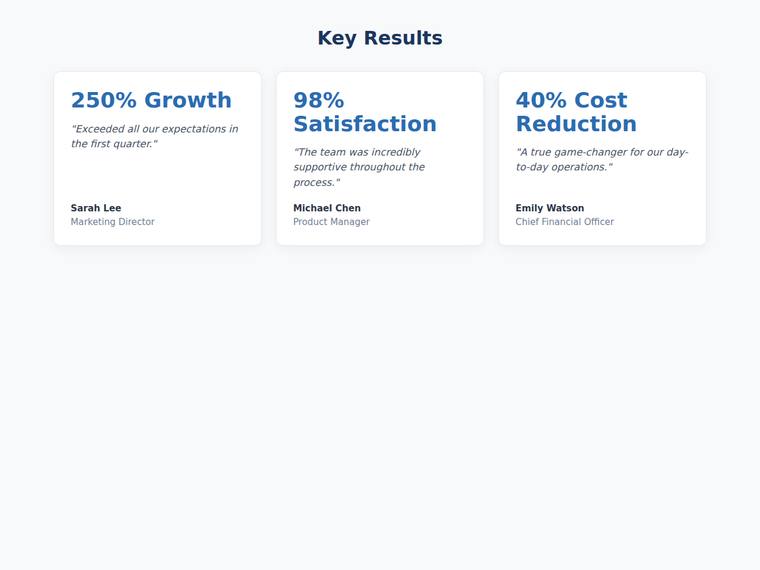
Stat and testimonial card grid
The same task, run on 28 models. Compare the outputs side by side, or open any one in a popup to inspect it.
Top result: claude-opus-4-8 (low reasoning) at 100.0% composite. Lowest: grok-4.3 at 96.1%. 28 models compared on this task.
How it ran
- Each model was given the brief below in a fresh, isolated session with no access to our tools, and returned a single self-contained index.html (inline CSS and JS, no external requests, no build step).
- The rendered output was scored 1 to 5 on brief fidelity, visual design, craft, and impact by a four-family vision panel - Anthropic (Claude Opus 4.8), OpenAI (GPT-5.5), Google (Gemini 3.1 Pro), and xAI (Grok 4.3) - using one identical prompt so the scores compare. The published judge score is leave-one-family-out: a model is never scored by a judge of its own family, so same-family self-preference is removed.
The brief
Build a self-contained results section as a single HTML file (`index.html`) that renders with no build step and no network calls (inline all CSS and JS). Requirements: - a clear section heading, - exactly three cards laid out as a responsive grid; each card pairs a headline statistic with a short testimonial quote and an attribution (name and role), - on a narrow screen the cards stack to a single column with no horizontal scroll. This is a visual piece: aim for balanced spacing, a clear hierarchy, and tasteful type and colour. Use plain, readable markup. No external fonts or scripts.